
Cách bảo vệ dữ liệu cá nhân trên Facebook: 7 bước đơn giản để đảm bảo an toàn online
Ngăn Facebook lấy dữ liệu cá nhân của bạn để đào tạo mô hình AI tạo sinh - Hướng dẫn xóa thông tin cá nhân trên Facebook để ngăn Meta sử dụng dữ liệu đó trong quá trình huấn luyện các mô hình trí tuệ nhân tạo tạo sinh
Theo đó, người dùng có thể truy cập vào trung tâm trợ giúp của Facebook và sau đó vào mục Quyền chủ thể dữ liệu với AI tạo sinh. Tại đây, Facebook cung cấp một biểu mẫu cho phép người dùng gửi các yêu cầu liên quan đến thông tin được sử dụng để đào tạo mô hình AI tổng hợp. Cụ thể, trong mục này, có 3 lựa chọn bao gồm: "Tôi muốn truy cập, tải xuống hoặc chỉnh sửa bất kỳ thông tin cá nhân nào từ bên thứ ba được sử dụng cho AI tạo sinh"; "Tôi có một vấn đề khác".
Với lựa chọn đầu tiên, người dùng có thể tải xuống và xem xét các dữ liệu cá nhân đã được thu thập bởi "bên thứ ba". Tuy nhiên, dữ liệu này vẫn được Meta sử dụng để đào tạo AI.
Nếu không muốn dữ liệu cá nhân của bạn được sử dụng để đào tạo Trí tuệ Nhân tạo (AI), hãy nhấp vào lựa chọn "Tôi muốn xóa mọi thông tin cá nhân của bên thứ ba được sử dụng cho việc tạo sinh AI". Sau đó, bạn vui lòng điền các thông tin cần thiết như quốc gia, tên và địa chỉ email vào biểu mẫu và nhấn gửi đi. Biểu mẫu này sẽ được Facebook xử lý tự động.
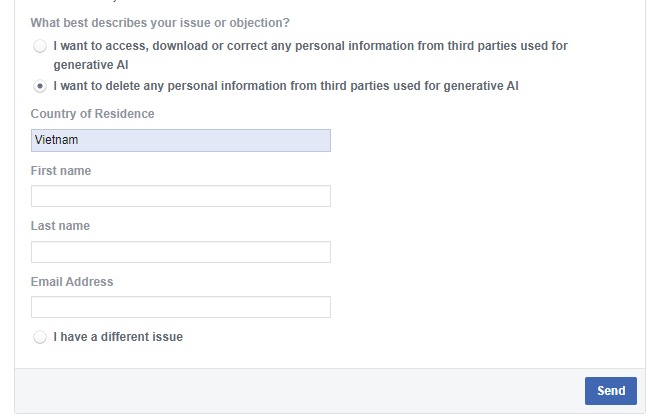
Người dùng có thể cung cấp thông tin trong biểu mẫu để yêu cầu Facebook xóa dữ liệu cá nhân, dữ liệu này có thể được sử dụng để đào tạo AI. (Ảnh chụp màn hình)
Theo CNBC, Facebook đã thể hiện sự quan tâm với công nghệ AI thông qua việc các công ty tạo ra các chatbot tiên tiến, có khả năng chuyển đổi văn bản đơn giản thành câu trả lời và hình ảnh phức tạp.
Tương tự như nhiều công ty công nghệ hàng đầu khác như Microsoft, OpenAI và Google, Meta đã thu thập một lượng lớn dữ liệu từ các bên thứ ba để huấn luyện các mô hình và phần mềm AI liên quan của mình.
Để đạt hiệu quả trong đào tạo mô hình AI, cần thu thập một lượng thông tin đáng kể từ các nguồn được cấp phép và công khai, như Meta đã trình bày trong một bài viết. Trên blog, Meta nhấn mạnh rằng họ sử dụng dữ liệu công khai từ web và thu thập dữ liệu được cấp phép từ các nhà cung cấp khác. Ví dụ, thông tin cá nhân như tên và thông tin liên hệ có thể được thu thập bởi Meta từ các bài đăng trên blog. Ngoài ra, các tương tác và bình luận của người dùng trên Instagram và Facebook cũng có thể được Meta sử dụng để đào tạo AI, theo CNBC.
Tuy nhiên, người phát ngôn của Meta cho biết mô hình ngôn ngữ lớn nguồn mở Llama 2 mới nhất của công ty này "chưa được đào tạo trên dữ liệu người dùng Meta và chúng tôi chưa phát hành bất kỳ tính năng AI tạo sinh nào cho người dùng trên hệ thống của chúng tôi"
Trong tuần trước, một liên minh bao gồm các cơ quan bảo vệ dữ liệu từ Anh, Canada, Thụy Sĩ và các nước khác đã phát đi một tuyên bố chung với Meta, Alphabet (công ty mẹ của TikTok - ByteDance), X (trước đây được gọi là Twitter), Microsoft và các công ty khác về việc thu thập dữ liệu và bảo vệ quyền riêng tư của người dùng.
Bức thư nhằm nhắc nhở các công ty công nghệ và truyền thông xã hội rằng họ cần tuân thủ các luật bảo vệ dữ liệu và quyền riêng tư khác nhau trên toàn cầu.
Nhóm cho biết trong tuyên bố: "Cá nhân cũng có thể thực hiện các biện pháp để bảo vệ thông tin cá nhân của mình khỏi việc thu thập dữ liệu và các công ty truyền thông xã hội đóng vai trò quan trọng trong việc cung cấp dịch vụ cho người dùng mà vẫn bảo vệ quyền riêng tư của họ".
Tham khảo CNBC
Quen thuộc tới mức ai cũng từng dùng qua một lần, một ứng dụng đã tồn tại gần 30 năm trên Windows bị 'khai tử'












