
Hành Trình Kỳ Lạ Của Tập Tin Robots.txt Của John Mueller
Tập tin robots.txt của John Mueller trở thành đối tượng tò mò vì các hướng dẫn kỳ lạ mà nó chứa và kích thước khổng lồ kỳ quái.
Sự Phát Hiện Đáng Ngạc Nhiên
Hành trình kỳ lạ của tập tin robots.txt của John Mueller bắt đầu khi một người dùng trên Reddit đăng rằng trang web của John Mueller đã bị gỡ khỏi chỉ mục, cho rằng trang web của Mueller đã vi phạm hệ thống Nội dung Hữu ích của Google và sau đó bị gỡ khỏi chỉ mục. Sự thật cuối cùng không đến nỗi dramatique như vậy nhưng vẫn có chút kỳ lạ.
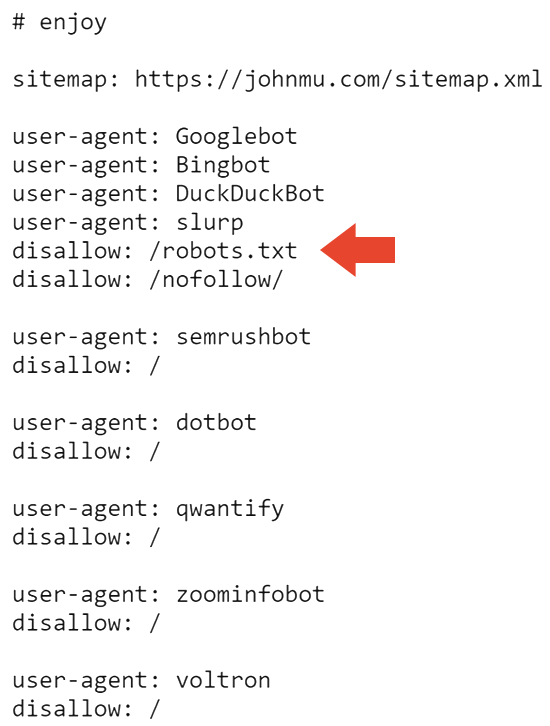
Dưới đây là phần trên cùng của tập tin robots.txt của Mueller với một lời chú thích nghịch ngợm cho những ai muốn nhìn vào.
Hành Trình Kỳ Lạ Của Tập Tin Robots.txt
Phần đầu tiên không phải mỗi ngày đều thấy là một lệnh Disallow trên tập tin robots.txt. Ai sử dụng tập tin robots.txt của họ để nói với Google không crawl tập tin robots.txt của họ?
Bây giờ chúng ta biết rồi.
Phần tiếp theo của tập tin robots.txt chặn tất cả các công cụ tìm kiếm khỏi crawl trang web và tập tin robots.txt.
Vì vậy có lẽ đó là lý do trang web bị gỡ khỏi chỉ mục trong Google. Nhưng điều đó không giải thích tại sao nó vẫn được chỉ mục bởi Bing.
Giải Thích Của John Mueller
Mueller dường như rất hài lòng khi mọi người quan tâm nhiều đến tập tin robots.txt của mình và ông đã đăng một giải thích trên LinkedIn về tình hình này.
Ông viết:
"Nhưng, vấn đề với tập tin là gì? Và tại sao trang web của bạn bị gỡ khỏi chỉ mục?
Một số người cho rằng điều này có thể là do các liên kết đến Google+. Điều đó hoàn toàn có thể. Và quay trở lại với tập tin robots.txt… nó ổn – ý là, nó như tôi muốn, và các crawler có thể xử lý được. Hoặc, họ nên có thể, nếu họ tuân thủ theo RFC9309."
Tiếp theo, ông nói rằng việc nofollow trên tập tin robots.txt chỉ đơn giản là để ngăn nó được chỉ mục như một tập tin HTML.
Ông giải thích:
''disallow: /robots.txt' – điều này có làm cho robot quay tròn không? Có khiến trang web của bạn bị gỡ khỏi chỉ mục không? Không.
Tập tin robots.txt của tôi chỉ có rất nhiều nội dung, và nó sẽ sạch sẽ hơn nếu nó không được chỉ mục với nội dung của nó. Điều này hoàn toàn ngăn chặn tập tin robots.txt khỏi việc được crawl vì mục đích chỉ mục.
Tôi cũng có thể sử dụng tiêu đề HTTP x-robots-tag với noindex, nhưng cách này tôi cũng có nó trong tập tin robots.txt."
Mueller cũng nói về kích thước tập tin này:
"Kích thước đến từ các bài kiểm tra của các công cụ kiểm tra robots.txt khác nhau mà đội ngũ của tôi và tôi đã làm việc. RFC nói rằng một crawler nên phân tích ít nhất 500 kibibytes (được thưởng thêm cho người đầu tiên giải thích loại snack đó là gì). Bạn phải dừng lại ở một nơi nào đó, bạn có thể tạo ra các trang vô tận (và tôi đã, và nhiều người cũng đã, một số thậm chí là cố ý). Thực tế thì điều gì sẽ xảy ra là hệ thống kiểm tra tập tin robots.txt (bộ phân tích) sẽ cắt ở một nơi nào đó."
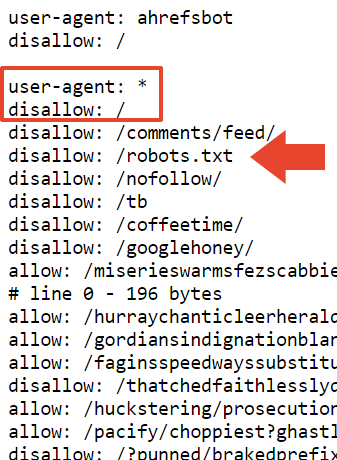
Ông cũng nói rằng ông đã thêm một disallow ở phần đó với hi vọng nó sẽ được hiểu như là một 'disallow chung' nhưng tôi không chắc chắn đây là disallow ông đang nói đến. Tập tin robots.txt của ông có chính xác 22,433 disallows trong đó.
"Tôi đã thêm một 'disallow: /' ở đầu phần đó, vì vậy hy vọng rằng nó sẽ được hiểu là một disallow chung. Có thể rằng bộ phân tích sẽ cắt ở một nơi khó chịu, như một dòng có 'allow: /cheeseisbest' và nó dừng ngay ở '/', điều đó sẽ đặt bộ phân tích vào tình thế bế tắc (và, điều thú vị! quy tắc allow sẽ ghi đè nếu bạn có cả 'allow: /' và 'disallow: /'). Điều này dường như rất ít khả năng xảy ra tuy nhiên."
Và đó là tập tin robots.txt kỳ lạ của John Mueller.
Tập tin robots.txt có thể xem tại đây:
https://johnmu.com/**robots.txt**
Hành Trình Kỳ Lạ Của Tập Tin Robots.txt
Khám Phá Thư Mục /nofollow/
Một trong những thư mục bị chặn bởi tập tin robots.txt của Mueller là /nofollow/ (một tên kỳ lạ cho một thư mục).
Thực ra không có gì trên trang đó ngoại trừ một số điều hướng trang web và từ 'Redirector'.
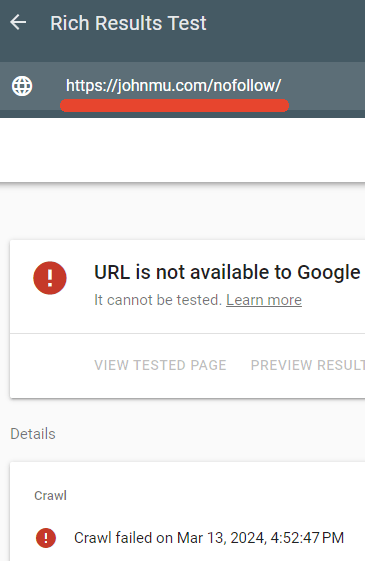
Tôi đã kiểm tra xem tập tin robots.txt có thực sự chặn trang đó hay không và đúng vậy.
Công cụ kiểm tra Kết quả phong phú của Google đã không thể crawl trang web /nofollow/.
Hành Trình Kỳ Lạ Của Tập Tin Robots.txt












